cs50: pset 8 (SQL, user authentication, API calls) and why early decisions matter
This is the big one! A stock trading app, allowing the user to register, log in, buy and sell shares and log out, all using Flask, SQLite and an API call to IEX, a service that returns stock pries in JSON.
pset8: finance (SQL, APIs, authentication)
The Brief
From the CS50 website:
Implement a website via which users can “buy” and “sell” stocks, a la the below.
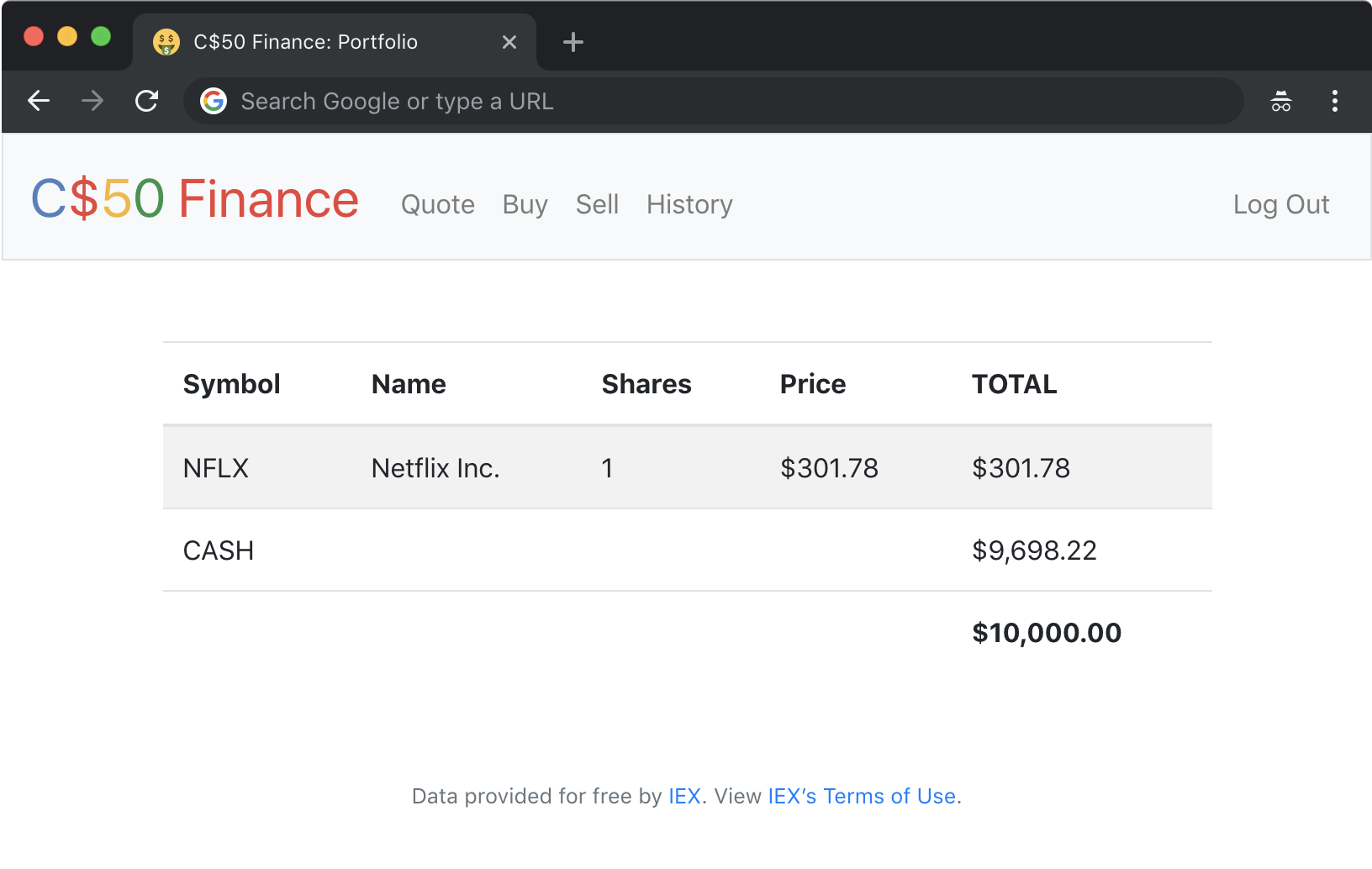
CS50 does start you off with a lot of the scaffolding in its distribution code. The basic site structure is there, and the student is required to first configure the Flask routes and complete the register, quote, buy, sell, history and index functions. These require you to use SQL to query and INSERT rows into tables of your choosing.
This was the most fun part to me. How to structure the data so it best met the functional requirements of the app?
This is where I feel my brain grunting and getting its game face on as it lifts the Olympic bar off the squat rack. (I won’t claim to be particularly strong in this arena. Think the puny chap from the old Mr Muscle adverts rather than Arnold himself).
 Thinking about data structures and how choices will affect your app downstream is seriously heavy lifting
Thinking about data structures and how choices will affect your app downstream is seriously heavy lifting
Thinking about data and the ‘what ifs’ of choosing one structure over another, trying to foresee how it will be used in the future and what functions are made easier or harder by setting the data up in one way or the other. There’s no better feeling than getting a crisp data structure and then designing a set of functions to manipulate, display and move it around your app.
I went with two tables:
users
This table holds users, a hash of the password, and how much cash they have:
| id | username | hash | cash |
|---|---|---|---|
| 1 | zack | pbkdf2:sha256:150000$hODLq4oF$… | 10000 |
| 2 | christina | pbkdf2:sha256:150000$wqI3BlDy$… | 8390.07 |
| 3 | loki | pbkdf2:sha256:150000$dOWo5ZH7$… | 7025.7 |
I didn’t create a column to hold each user’s current portfolio of holdings and its value. I might have done this by having an arbitray number of additional columns (holding_1, holding_2, holding_3…) but to attempt do this for every single possible stock under the sun (and future stocks not yet listed?!), or even creating columns dynamically, would have been very, very limiting.
I could have bodged it by creating a VARCHAR column to hold a JSON string with key:value pairs like { holding : quantity }. This would have recorded each user’s state of the current portfolio, but in a way that would be incredibly inefficient to search and sort (‘Hey SQLite, find me the user with the greatest holding of AAPL stocks’). It would also be vulnerable if any function that acted on it messed up the JSON string. This is a Bad Idea.
A better way to do this would be to create a second table, perhaps called holdings to store each user’s current portfolio. This would look something like this:
| id | user_id | stock | quantity |
|---|---|---|---|
| 1 | 3 | AAPL | 3 |
| 2 | 3 | GOOGL | 7 |
| 3 | 3 | MARS | 15 |
| … | … | … | … |
…and so on for all users
This holdings table would show loki’s (user id 3) stocks and how much he owns. Loki is our pet cat. He’s heavily weighted towards Mars, the company that manufactures his favourite pet food, Whiskas. Arguably his strategy here is weakened in that his primary food source and retirement funds hinge on the success of the same, single company. (I always said he was too impulsive. I’d diversify if I were you, Loki.)
 Loki the cat: bullish on pet food manufacturers
Loki the cat: bullish on pet food manufacturers
When the app is required to display the user’s current holdings, it could then make a SQL query to join the user and holdings tables and return the relevant rows.
But I digress. I didn’t go this far in CS50. Instead, I created a transactions table to hold a record of all buy and sell orders:
transactions
| id | user | symbol | shares | price | datetime |
|---|---|---|---|---|---|
| 1 | 1 | AAPL | -1 | 293.65 | 2020-01-01 14:23:04 |
| 2 | 3 | MSFT | -24 | 157.7 | 2020-01-01 14:27:39 |
| 3 | 3 | GOOGL | 1 | 1339.39 | 2020-01-01 14:27:52 |
A note on column names
I did a really naughty thing here.
My column naming is awful. In SQL (and in almost all areas of computer science) many special strings/names are reserved and can’t mustn’t be used as variable names, function or method names, or in this case SQL column names. (I say musn’t because, frustratingly, many languages/technologies will permit you to mis-name things without telling you.)
Above, I’ve used id to name the primary key column. id isn’t strictly a reserved word in SQL, it’s just bad practice. Every table needs a primary key, so every table under this naming convention will have an id column. This could get very confusing very fast and may result in the wrong column being dropped, wrong data inserted or other downright confusing and Bad Things. Instead, I should’ve named it transaction_id to differentiate it.
datetime is getting a bit close to the wire. It’s also not a reserved word in SQL, but it’s very close to timestamp, which is. In retrospect, I’d have gone with transaction_datetime.
Calculating portfolio from transactions
To get users’ portfolios without creating a third table, and without creating a Python function in the Controller part of the app to calculate it, I created a SQL view. A view is the result of a stored query on one or more other tables, and it can be queried itself just like it were a table! I created it using the below SQL:
CREATE VIEW v_holdings AS SELECT * FROM (SELECT username, symbol, sum(shares) AS shares FROM v_transactions GROUP BY symbol, username) WHERE shares != 0
Arguably, it would be more performant to have a holding table instead, whereby a new row is inserted or existing row updated only when a user buys and sells. That way, the processing only occurs once.
With a SQL view, the whole transactions table is conditionally queried every time information about holdings is required. This will slower and slower as the number of rows in the transactions and users tables increases.
I did it this way because I wanted to expand my knowledge of SQL to include views and, knowing it would still meet the functional requirements of CS50, I’m glad I did. If I were doing this for real I’d invest much more time in learning the performance aspects of SQL database design, which is a complicated subject many very intelligent people make long careers out of. A topic for another day.
What did I learn from this?
This challenge got me thinking about the way data is stored, edited and retrieved and how choices made very early on in an application or service’s development can become constraining pretty quickly.
I quickly found myself painted in to a corner of my own doing and having to go back and re-assess my data model, ultimately coming up with the compromise I’ve described above. Though this was frustrating, I feel it was invaluable experience in training me to recognise the second and third order effects of my choices.
This was the first part of CS50 where I really saw that, because the problem naturally casuses you to create your own interdepencies. You the developer create your data model and you have to make it work with the functions that you define and call. Wowser.
I found this invigorating.
It’s a truism that you live and die by your decisions in life, and this exercise really neatly illustrated this for me in software development. Early, seemingly insignificant, design decisions can have effects increasing in magnitude as the application or service gets closer to appearing in front of real users.
Just as my previous revelation whilst hacking and bodging my way through debugging the caesar.c problem set, recognising this helped me understand that the specific language or technology is less important than having a good grasp of the principles and core skills in software engineering.
Early decisions matter.